
Today I thought I'd get a few things off my chest.
Whenever I review code, look at old code or have the job of maintaining code (not my favourite part of the job by a long shot) I am often left dumbfounded. I see the same old mistakes being made regardless of where I have worked. You will often hear me saying,"Whoever wrote this should be shot!!".
The most annoying part is that in many places the developers agree about the best way to code but quickly use the excuse of "I don't have enough time", or "Well it's done now, so don't worry" to not code properly. My experience tells me it is often the most experienced developer(s) who are the hardest to convince of solid development standards with the terms "Old dog" and "new tricks" preeminent in my mind....
IMHO the difference between a run of the mill programmer (I've worked with plenty of these) and a good one (fewer but they are out there) is adherence to the little details that make long term maintainability of your code as easy as it should. This is especially true considering the inevitable change and enhancement that is required during an applications growth and evolution. I have espoused the standard development quote that 90% of an applications life cycle is maintenance numerous times before.
Anyhow, my post today is a list of pet hates that I see when people are
1. Legacy commented out code.
I recently worked on some maintenance and had to work through some action diagram code. Using the Find Services option within 2E I started to quickly get frustrated that the majority of the usages that were commented out.
What was worse still is that there were developer comments (from 2002) stating that the code was commented out and I know that this area has been enhanced many times since. There is simply no reason to keep such old code. The developer concerned is normally quite good but has a couple of really bad habits like this one.
Here is a snippet of code from an old function (screen print kindly shown with permission). Note, I have redacted any client or developer or brand comments (hence some empty white space).




I am all for commenting out code as part of debugging, rapid prototyping, unit testing and quick wins (hot fixes) where you are not quite sure of the change you are making, but please annotate when and why. However, I am aware that some of this code was moved to their own program(s) so IMHO should just have been removed.
Associated hates:
- Having to weed through the chaff to get to the code to change.
- Any old code will not have been maintained so will not (often) be fit for purpose (if you decided to uncomment it) so why leave it there.
- Extra impact analysis (especially for internal functions).
- Confusion with the impact analysis usage. A future post is planned for this.
- Better to take a version.
- Commenting out code doesn't change the timestamp for the AD line so we don't know when it was commented out.
Here is the same code with the bad commented out code and legacy comments removed.


2. "GET All fields" RTVOBJ not doing as described.
Every 2E developer has written the standard RTVOBJ that returns the full record. Yes, we all have forgotten the *MOVE ALL, but my biggest annoyance is when people don't visit these functions when the underlying file structure changes.
Imagine the "*GET", "GET Record", "Get All", "RTV All Fields" function without the new fields as parameter.

The next developer comes along and low and behold, there are a few fields missing. Then they create a new one called Get All (New) and probably flag the other one with some kind of encoding system like DNU for Do Not Use etc.
Associated hates:
Numerous versions of the same type of function. Too many choices.
Description vs reality can be misleading and frustrating.
Tip: If you have to change the file, you may as well change the "Full Record" type function as you have to regenerate up everything anyhow.
3. Using all 9 parameter definition lines for functions parameters.
In the old days when we only had *FIELD, Access Path(s) or Structure files for defining parameters it could sometimes get a little busy and we'd fill the 9 lines leaving limited options for the next developer. We shouldn't create structure files just for the sake of it, after all, their primary purposes was for consistency of repeating data groups like audit stamps etc not for easier passing of parameters.

Since version 4.0 (over 20 years) we've been able to define parameter arrays. There really is no excuse now for taking up the last line of a functions parameter block unless "I don't have time" or "I'll do it when we get to 10" is a valid reason.

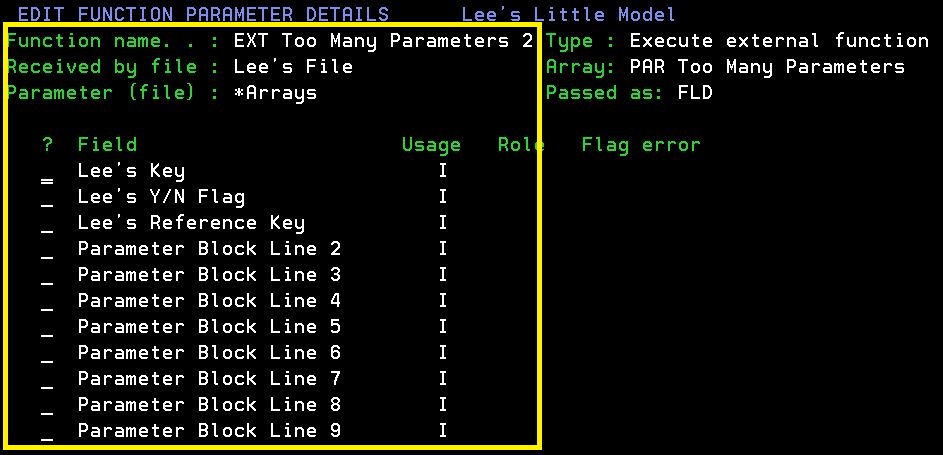
I still think that even using parameter arrays as being a bastardised solution for this problem and that 2E should just have had more that 9 lines....but it is the lesser or two evils.
This is the tip of the iceberg. Plenty more to follow I am sure.
Thanks for reading.
Lee.