
When this happens to me I usually like to review the entries in the journal and analyse the database I/O data to get a feel for what is happening.
So how do I go about doing this.....
Firstly I would identify the journal that is being used. This may change from time to time so it is best to check each and every time you perform these steps. Do a WRKOBJ for the library and main file you are trying to track entries for.
WRKOBJ OBJ(DATALIB/TARGETFILE)
Take option 8=Display Description and page down three
times or do a DSPFD for the given file and search of the Journal name from the output.
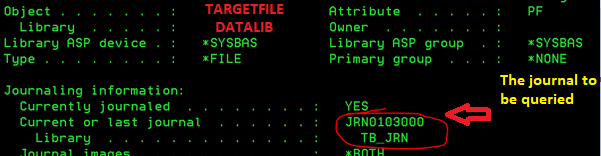
Now you know the journal. Perform the action(s) you wish to monitor for
and note the times. (start and Finish)
You can then extract this data from the journal using the DSPJRN command. Below is an example of isolating the entries in a particular environment. I have gone for all files in library MSLTSTDTA in this example but there are plenty of filtering options. I then chose to output the resultant data into a file so that I could query it more easily.
DSPJRN JRN(TB_JRN/JRN0103000) FILE((DATALIB/*ALL)) FROMTIME(280222 074200) TOTIME(280222 074300) OUTPUT(*OUTFILE) OUTFILE(LDARE/LD_JOURNAL). The OUTFILE keyword is optional but will help if you want to perform some queries are a saved dataset.
Please note that the date and time parameters are particularly important as this can take a while to extract otherwise. Just this small sample took a few seconds interactively. If querying for more, you might want to consider submitting the task.
The resultant data file is formatted as follows:-

The main item to look for is the 'Entry Type'. These codes identify when data is inserted,
updated or deleted from the database table as well as if it is rolled back.
https://www.ibm.com/docs/en/i/7.2?topic=information-journal-code-descriptions
|
Entry Code |
Description |
|
BR |
Before-image of record updated for rollback
operation |
|
DR |
Record deleted for rollback operation |
|
PT |
Record added to a physical file member. If the
file is set up to reuse deleted records, then you may receive either a PT or
PX journal entry for the change |
|
PX |
Record added directly by RRN (relative record
number) to a physical file member. If the file is set up to reuse deleted
records, then you may receive either a PT or PX journal entry for the change |
|
UB |
Before-image of a record that is updated in
the physical file member (this entry is present only if IMAGES(*BOTH) is
specified on the STRJRNPF command) |
|
UP |
After-image of a record that is updated in the
physical file member |
|
UR |
After-image of a record that is updated for
rollback information |
For a full list of journaling codes you can use this link within the IBM i documentation.
https://www.ibm.com/docs/en/i/7.2?topic=information-all-journal-entries-by-code-type






